各软件包版本及下载地址如下
http://archive.apache.org/dist/zookeeper/zookeeper-3.4.8/zookeeper-3.4.8.tar.gz
https://archive.apache.org/dist/hadoop/common/hadoop-2.7.1/hadoop-2.7.1.tar.gz
http://archive.apache.org/dist/hive/hive-1.2.0/apache-hive-1.2.0-bin.tar.gz
http://archive.apache.org/dist/hbase/0.98.17/hbase-0.98.17-hadoop2-bin.tar.gz
http://archive.apache.org/dist/spark/spark-2.1.0/spark-2.1.0-bin-hadoop2.7.tgz
集群示意图
本次采用三个节点安装hadoop分布式集群,使用zookeeper进行分布式系统的协调与管理,安装HBASE分布式数据库,Hive数仓工具,Spark实时计算平台,具体结构如下图
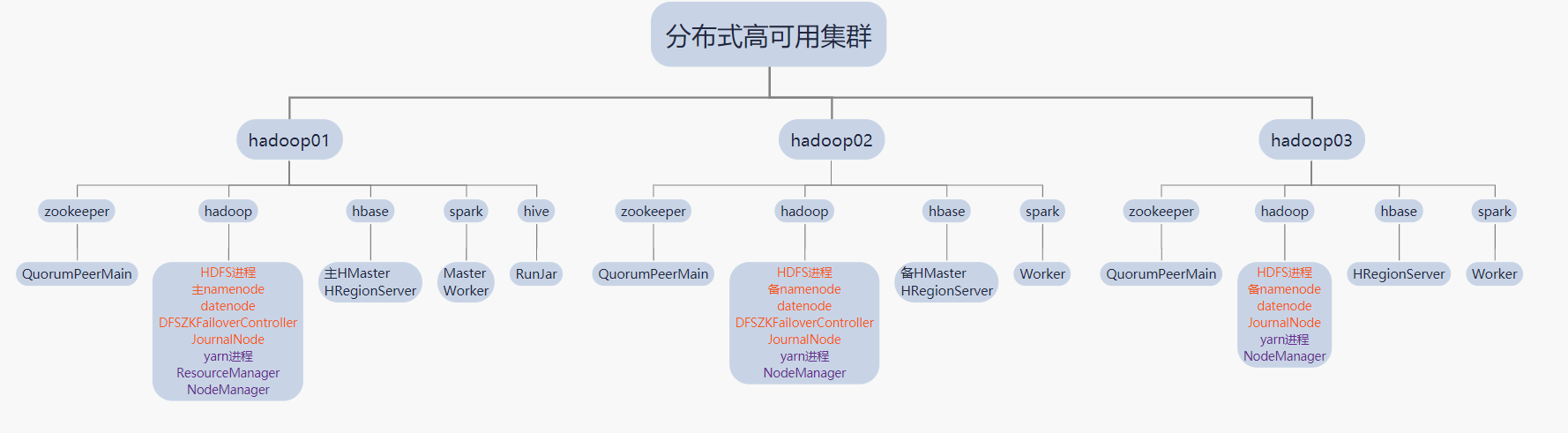
分布式集群进程.png
操作系统环境准备
由于用于学习不需要太高的配置, 使用VMware WorkStation搭建三个节点的虚拟机,操作系统centos7,内存越大越好(我给的每个节点3G), 处理器数量1颗, 存储30G
1.三个节点设置防火墙访问策略,保证三个节点之间能正常通信, 我这里直接关闭三个节点的防火墙.
临时关闭防火墙 [root@hadoop01 sorftware]# systemctl stop firewalld.service 查看防火墙状态 [root@hadoop01 sorftware]# systemctl status firewalld.service 设置禁止开机自启动 ,永久关闭防火墙 [root@hadoop01 sorftware]# systemctl disable firewalld.service
2.关闭selinux,避免不必要的权限错误
SELinux共有3个状态enforcing (执行中), permissive (不执行但产生警告),disabled(关闭)
查看selinux状态,使用getenforce命令
[root@hadoop01 ~]# getenforce
Disabled
更改selinux状态为disable,修改/etc/selinux/config为如下,重启机器生效
[root@hadoop01 ~]# cat /etc/selinux/config
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=disabled
# SELINUXTYPE= can take one of three values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted
3.做好节点之间的免密登录
略
4.设置统一对时服务器
如果不能连接互联网可以自己搭建时钟服务器,我这边采用与互联网对时服务器对时 需先安装ntpdate服务 [root@hadoop01 home]# ntpdate ntp1.aliyun.com 22 Apr 23:22:28 ntpdate[19861]: adjust time server 120.25.115.20 offset -0.385698 sec [root@hadoop02 sorftware]# ntpdate ntp1.aliyun.com 22 Apr 23:22:34 ntpdate[16962]: adjust time server 120.25.115.20 offset -0.384993 sec [root@hadoop03 ~]# ntpdate ntp1.aliyun.com 22 Apr 23:24:00 ntpdate[10194]: adjust time server 120.25.115.20 offset -0.337555 sec
5.安装jdk,设置好环境变量
[root@hadoop01 home]# java -version java version "1.8.0_212" Java(TM) SE Runtime Environment (build 1.8.0_212-b10) Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode) [root@hadoop01 home]# javac -version javac 1.8.0_212 [root@hadoop01 home]# echo $JAVA_HOME /usr/local/jdk1.8.0_212 [root@hadoop01 home]# echo $CLASSPATH .:/usr/local/jdk1.8.0_212/lib/tools.jar [root@hadoop01 home]#
6.修改主机名,做好主机名IP映射
第一个节点hadoop01 [root@hadoop01 home]# hostname hadoop01 [root@hadoop01 home]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.31.200 hadoop01 192.168.31.201 hadoop02 192.168.31.202 hadoop03 [root@hadoop01 home]# 第二个节点hadoop02 [root@hadoop02 sorftware]# hostname hadoop02 [root@hadoop02 sorftware]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.31.200 hadoop01 192.168.31.201 hadoop02 192.168.31.202 hadoop03 第三个节点hadoop03 [root@hadoop03 ~]# hostname hadoop03 [root@hadoop03 ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.31.200 hadoop01 192.168.31.201 hadoop02 192.168.31.202 hadoop03 [root@hadoop03 ~]#
7.上传安装包
前面系统环境都已经设置完成,下面上传安装包,准备安装
我将所有组件都安装至/opt/sorftware目录 [root@hadoop01 sorftware]# pwd /opt/sorftware [root@hadoop01 sorftware]# ls |grep tar.gz apache-flume-1.6.0-bin.tar.gz apache-hive-1.2.0-bin.tar.gz apache-phoenix-4.8.1-HBase-0.98-bin.tar.gz hadoop-2.7.1_64bit.tar.gz hbase-0.98.17-hadoop2-bin.tar.gz sqoop-1.4.4.bin__hadoop-2.0.4-alpha.tar.gz zookeeper-3.4.8.tar.gz spark-2.0.1-bin-hadoop2.7.tgz
安装zookeeper
Zookeeper是一个分布式的协调服务框架,Zookeeper可以解决分布式环境常见的问题:集群管理、统一命名服务,信息配置管理,分布式锁等等.可以说zookeeper是真整个haodoop动物生态圈的铲屎官.
1.解压zookeeper的安装包
[root@hadoop01 sorftware]# cd /opt/sorftware/
[root@hadoop01 sorftware]# tar -zxvf zookeeper-3.4.8.tar.gz
#解压出来如下
[root@hadoop01 sorftware]# cd zookeeper-3.4.8
[root@hadoop01 zookeeper-3.4.8]# ls
bin contrib ivy.xml README_packaging.txt zookeeper-3.4.8.jar
build.xml dist-maven lib README.txt zookeeper-3.4.8.jar.asc
CHANGES.txt docs LICENSE.txt recipes zookeeper-3.4.8.jar.md5
conf ivysettings.xml NOTICE.txt data-src zookeeper-3.4.8.jar.sha1
[root@hadoop01 zookeeper-3.4.8]#
#配置环境变量如下,便于使用zookeeper的一些命令,设置完成后source /etc/profile生效
[root@hadoop01 zookeeper]# cat /etc/profile|grep ZOOKEEPER_HOME
ZOOKEEPER_HOME=/opt/sorftware/zookeeper-3.4.8
export PATH=$PATH:$ZOOKEEPER_HOME/bin:$FLUME_HOME/bin:$HIVE_HOME/bin:$SQOOP_HOME/bin:$HBASE_HOME/bin:$KAFKA_HOME/bin:$SPARK_HOME/bin
[root@hadoop01 zookeeper]#
2.配置zookeeper
1.切换到zookeeper安装目录的conf目录,其中有一个zoo_sample.cfg的配置文件,这个一个配置模板文件,我们需要复制这个文件,并重命名为 zoo.cfg。zoo.cfg才是真正的配置文件 [root@hadoop01 zookeeper-3.4.8]# cd $ZOOKEEPER_HOME/conf [root@hadoop01 conf]# pwd /opt/sorftware/zookeeper-3.4.8/conf [root@hadoop01 conf]# cp zoo_sample.cfg zoo.cfg [root@hadoop01 conf]# ls configuration.xsl log4j.properties zoo.cfg zookeeper.out zoo_sample.cfg
zoo.cfg配置如下 [root@hadoop01 conf]# cat zoo.cfg |grep -v "#" tickTime=2000 initLimit=10 syncLimit=5 dataDir=/opt/sorftware/zookeeper clientPort=2181 server.1=192.168.31.200:2888:3888 server.2=192.168.31.201:2888:3888 server.3=192.168.31.202:2888:3888 配置说明: tickTime: zookeeper中使用的基本时间单位, 毫秒值. dataDir: 数据目录. 可以是任意目录. dataLogDir: log目录, 同样可以是任意目录. 如果没有设置该参数, 将使用和dataDir相同的设置. clientPort: 监听client连接的端口号 initLimit: zookeeper集群中的包含多台server, 其中一台为leader, 集群中其余的server为follower. initLimit参数配置初始化连接时, follower和leader之间的最长心跳时间. 此时该参数设置为5, 说明时间限制为5倍tickTime, 即5*2000=10000ms=10s. syncLimit: 该参数配置leader和follower之间发送消息, 请求和应答的最大时间长度. 此时该参数设置为2, 说明时间限制为2倍tickTime, 即4000ms. server:是关键字,后面的数字是选举id,在zk集群的选举过程中会用到。补充:此数字不固定,但是需要注意选举id不能重复,相互之间要能比较大小然后保存退出. 例如:192.168.31.200:2888:3888 ,说明:2888原子广播端口,3888选举端口 zookeeper有几个节点,就配置几个server;
2.创建dataDir,添加myid,myid应与配置文件对应,我这里三个节点分别为1,2,3
[root@hadoop01 /]# mkdir -p /opt/sorftware/zookeeper
#第一个节点haoop01
[root@hadoop01 zookeeper]# cat /opt/sorftware/zookeeper/myid
1
[root@hadoop01 zookeeper]#
3.配置集群模式
将hadoop01节点上的zookeeper远程拷贝到hadoop02和hadoop03,拷贝完成之后需要创建dataDir,并创建myid。
#拷贝文件
[root@hadoop01 sorftware]# scp -r ./zookeeper-3.4.8 root@hadoop02:$PWD
[root@hadoop01 sorftware]# scp -r ./zookeeper-3.4.8 root@hadoop03:$PWD
#另外两个节点记得创建dataDir目录,创建myid文件
4.启动zookeeper
#我这里配置了环境变量可以直接使用zk的命令,如果没配置需要去zookeeper安装的bin目录下执行
#三个节点分别执行
[root@hadoop01 zookeeper-3.4.8]# zkServer.sh start
#查看状态使用如下命令,zookeeper节点有三种状态,leader,follower,Observer
#我们这里配置了三个节点都参与选举,应该有一个leader,两个follower,选举采用ZAB协议.
[root@hadoop01 zookeeper-3.4.8]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/sorftware/zookeeper-3.4.8/bin/../conf/zoo.cfg
Mode: leader
[root@hadoop02 zookeeper-3.4.8]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/sorftware/zookeeper-3.4.8/bin/../conf/zoo.cfg
Mode: follower
[root@hadoop03 zookeeper-3.4.8]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/sorftware/zookeeper-3.4.8/bin/../conf/zoo.cfg
Mode: follower
#输入jps命令,查看zookeeper的进程
[root@hadoop03 zookeeper-3.4.8]# jps|grep QuorumPeerMain
7722 QuorumPeerMain
5.使用zookeeper
#zookeeper属于hadoop集群管理者,必须最先启动,最后关闭
启动命令:zkServer.sh start
关闭命令:zkServer.sh stop
查看状态:zkServer.sh status
后面补充
安装hadoop
Apache的Hadoop是一个开源的、可靠的、可扩展的系统架构,可利用分布式架构来存储海量数据,以及实现分布式的计算。Hadoop的两个作用:①存储海量数据 ②计算海量数据.下面介绍一下安装过程;先只在主节点配置,等配置好之后直接拷贝至备节点和数据节点.
1.在主节点解压hadoop安装包,配置环境变量
[root@hadoop01 sorftware]# pwd
/opt/sorftware
[root@hadoop01 sorftware]# tar -zxvf hadoop-2.7.1_64bit.tar.gz
#在/etc/profile加入hadoop环境变量,并source /etc/profile,这样方便后面使用hadoop命令
root@hadoop01 hadoop]# cat /etc/profile|grep HADOOP_HOME
#hadoop安装目录
HADOOP_HOME=/opt/sorftware/hadoop-2.7.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
2.进入hadoop安装目录,$HADOOP_HOME/etc/hadoop/,配置hadoop-env.sh
#配置jdk安装所在目录
export JAVA_HOME=/usr/local/jdk1.8.0_212
#配置hadoop配置文件所在目录
export HADOOP_CONF_DIR=/opt/software/hadoop-2.7.1/etc/hadoop
#执行source ./hadoop-env.sh,立即生效
3.进入hadoop安装目录,$HADOOP_HOME/etc/hadoop/,配置core-site.xml
<configuration>
<property>
<!--指定hdfs的nameservice为整个集群起一个别名 -->
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<!--指定Hadoop数据临时存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/sorftware/hadoop-2.7.1/tmp</value>
</property>
<!--指定zookeeper的存放地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
</configuration>
4.进入hadoop安装目录,$HADOOP_HOME/etc/hadoop/,配置hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!--执行hdfs的nameservice为ns,注意要和core-site.xml中的名称保持一致-->
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<!--ns集群下有两个namenode,分别为nn1, nn2-->
<property>
<name>dfs.ha.namenodes.ns</name>
<!--nn1的RPC通信-->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>hadoop01:9000</value>
</property>
<!--nn1的http通信-->
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>hadoop01:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>hadoop02:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>hadoop02:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/ns</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/sorftware/hadoop-2.7.1/tmp/journal</value>
</property>
<!-- 开启NameNode故障时自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制 -->
<property>
<name>dfs.ha.fencing.methods</name>
<!-- 使用隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!--配置namenode存放元数据的目录,可以不配置,如果不配置则默认放到hadoop.tmp.dir下-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///opt/sorftware/hadoop-2.7.1/tmp/hdfs/name</value>
</property>
<!--配置datanode存放元数据的目录,可以不配置,如果不配置则默认放到hadoop.tmp.dir下-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///opt/sorftware/hadoop-2.7.1/tmp/hdfs/data</value>
</property>
<!--配置副本数量-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--设置用户的操作权限,false表示关闭权限验证,任何用户都可以操作-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
5.进入hadoop安装目录,$HADOOP_HOME/etc/hadoop/,配置mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<!--指定mapreduce运行在yarn上,也可以调整为local-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
6.进入hadoop安装目录,$HADOOP_HOME/etc/hadoop/,配置yarn-site.xml
<?xml version="1.0"?>
<configuration>
<!-- Site specific YARN configuration properties -->
<!--配置yarn的高可用-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--指定两个resourcemaneger的名称-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!--配置rm1的主机-->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop01</value>
</property>
<!--配置rm2的主机-->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop03</value>
</property>
<!--开启yarn恢复机制-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--执行rm恢复机制实现类-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!--配置zookeeper的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
<!--执行yarn集群的别名-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>ns-yarn</value>
</property>
<!-- 指定nodemanager启动时加载server的方式为shuffle server -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定resourcemanager地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop03</value>
</property>
</configuration>
7.进入hadoop安装目录,$HADOOP_HOME/etc/hadoop/,配置slave文件
[root@hadoop01 hadoop]# cat slaves hadoop01 hadoop02 hadoop03
8.将hadoop安装目录远程copy到其他2台机器上,其他节点也设置环境变量
[root@hadoop01 sorftware]# cd /opt/sorftware/ 向hadoop02节点传输: [root@hadoop01 sorftware]# scp -r ./hadoop-2.7.1 root@hadoop02:$PWD 向hadoop03节点传输: [root@hadoop01 sorftware]# scp -r ./hadoop-2.7.1 root@hadoop03:$PWD
9.根据配置文件,创建相关的文件夹,用来存放对应数据
指定Hadoop数据临时存放目录
指定JournalNode在本地磁盘存放数据的位置
10.hadoop集群第一次启动
1.启动zookeeper集群,上面我以经开启这里就不再执行,检查一下状态如下:
[root@hadoop01 hadoop]# zkServer.sh status ZooKeeper JMX enabled by default Using config: /opt/sorftware/zookeeper-3.4.8/bin/../conf/zoo.cfg Mode: leader [root@hadoop02 zookeeper-3.4.8]# zkServer.sh status ZooKeeper JMX enabled by default Using config: /opt/sorftware/zookeeper-3.4.8/bin/../conf/zoo.cfg Mode: follower [root@hadoop03 zookeeper-3.4.8]# zkServer.sh status ZooKeeper JMX enabled by default Using config: /opt/sorftware/zookeeper-3.4.8/bin/../conf/zoo.cfg Mode: follower
2.格式化zookeeper
#在zk的leader节点上执行:hdfs zkfc -formatZK,这个指令的作用是在zookeeper集群上生成hadoop-ha节点(ns节点),出现如下信息表示成功
INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/ns in ZK.
#可以在zookeeper上查看,使用zkCli.sh登录
[zk: localhost:2181(CONNECTED) 5] ls /hadoop-ha/ns/Active
ActiveBreadCrumb ActiveStandbyElectorLock
3.启动journalnode进程
#在三个节点上分别启动journalnode进程,该进程作用保证主备NameNode数据同步
hadoop-daemon.sh start journalnode
#jps查看多了JournalNode进程
[root@hadoop01 hadoop]# jps|grep JournalNode
8233 JournalNode
4.主节点格式化namenode,并启动NameNode进程
#格式化NameNode
hadoop namenode -format
#启动主节点namenode进程
hadoop-daemon start namenode
#jps查看多了一个DataNode进程
[root@hadoop01 hadoop]# jps|grep Name
7933 NameNode
5.把备节点hadoop02变为standby namenode节点
#格式化备节点
hdfs namenode -bootstrapStandby
#启动备节点NameNode进程
hadoop-daemon.sh start namenode
#jps查看多了一个NameNode进程
[root@hadoop01 hadoop]# jps|grep Name
7933 NameNode
6.在三个节点上分别启动datenode进程
#三个节点分别启动
hadoop-daemon.sh start datanode
#jps查看多了一个DataNode进程
[root@hadoop01 hadoop]# jps|grep DataNode
8039 DataNode
7.主备节点启动主备故障切换进程,在50070web页面可以清楚看的主备节点的状态
#主备节点分别执行该命令
hadoop-daemon.sh start zkfc
#jps查看多了一个进程名称
[root@hadoop01 hadoop]# jps|grep DFSZKFailoverController
8421 DFSZKFailoverController
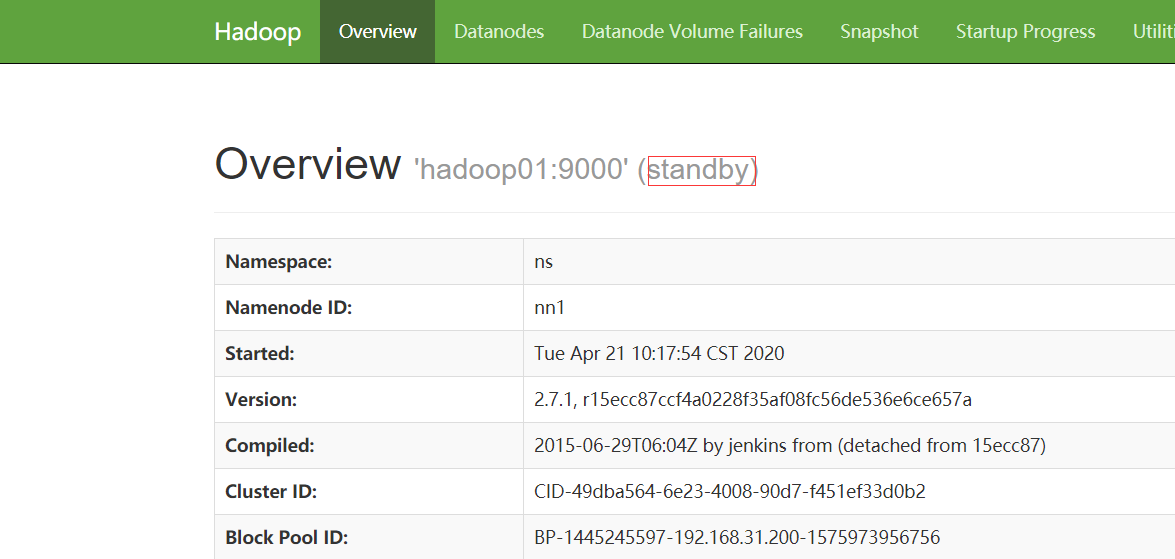
standby.png
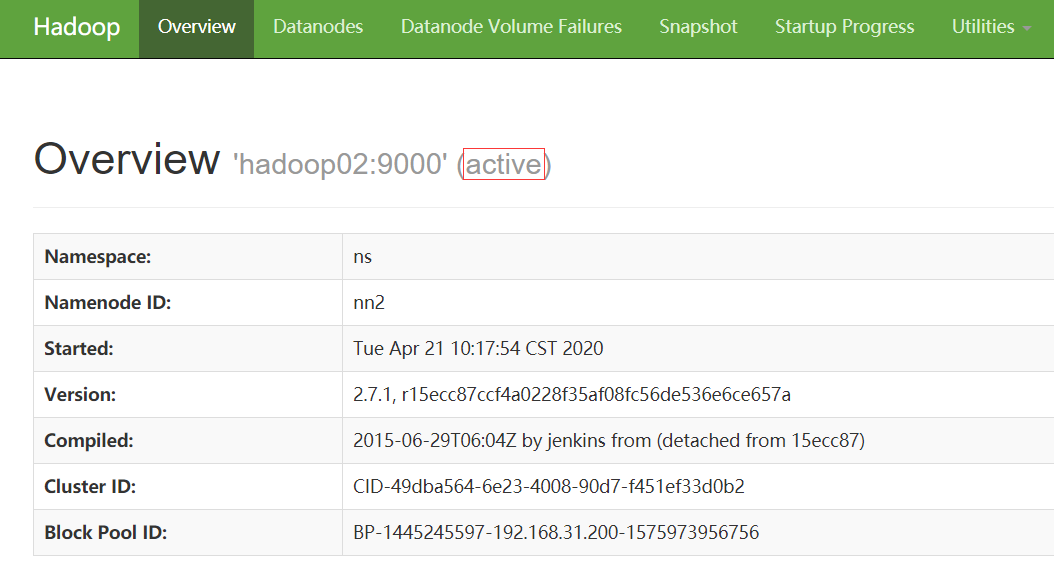
image.png
8.启动yarn
#1.在hadoop03上启动yarn的resouceManager
[root@hadoop03 ~]# yarn-daemon.sh start resourcemanager
#jps查看进程多了一个ResourceManager进程
[root@hadoop03 ~]# jps|grep ResourceManager
11911 ResourceManager
#2.在主节点启动yarn所有进程使用start-yarn.sh
#也可以在每个yarn节点上使用yarn-daemon.sh脚本分别收动启动resourcemanager,和NodeManager
[root@hadoop01 hadoop]# start-yarn.sh
9.hadoop相关进程作用及启动先后顺序
#HDFS有NameNode(主备节点),DataNode(数据节点),JournalNode(主备以及数据节点),DFSZKFailoverController(主备节点)这几个进程
#1.先启动JournalNode(保证主备NameNode数据同步)
hadoop-daemon.sh start journalnode
#2.启动NameNode(管理元数据,与名称空间)
hadoop-daemon.sh start namenode
#3.启动DFSZKFailoverController(主备故障切换)
hadoop-daemon.sh start zkfc
#4.启动DataNode(数据节点,数据读写)
hadoop-daemon.sh start datanode
#关闭进程,直接jps找到该进程的进程号
kill -9 进程号
#在主节点可以执行start-dfs.sh一次性启动所有hdfs相关进程
#yarn 只有ResourceManager(主备),NodeManager
#1.先启动ResourceManager(资源管理,调度)
yarn-daemon.sh start resourcemanager
#2.再启动NodeManager(每个节点上的资源和任务管理器)
yarn-daemon.sh start nodemanager
#关闭进程,直接jps找到该进程的进程号
kill -9 进程号
#在主节点可以执行start-yarn.sh一次性启动所有yarn相关进程
10.现在hdfs与yarn以经安装好了,可以通过执行一个单词统计的mapreduce任务使用一下集群
package cn.ceshi.test;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
//Driver类
public class WordCountDriver {
public static void main(String[] args) throws ClassNotFoundException, IOException, InterruptedException {
// 向YARN申请一个JOB用于执行MapTask
Job job = Job.getInstance(new Configuration());
// 设置入口类
job.setJarByClass(WordCountDriver.class);
// 设置Mapper类
job.setMapperClass(WordCountMapper.class);
// 设置Reducer类
job.setReducerClass(WordCountReduce.class);
// 设置分区类
//job.setPartitionerClass(AddrPartitioner.class);
// 每一个分区要对应一个ReduceTask,默认情况下,只有一个分区也就只有一个ReduceTask;
// 如果不指定,无论有多少分区,还是只有一个
//job.setNumReduceTasks(3);
// mapper的输出
//job.setMapOutputKeyClass(Text.class);
//job.setMapOutputValueClass(LongWritable.class);
// 设置Reduceer的输出
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 设置要处理的文件
FileInputFormat.addInputPath(job, new Path("hdfs://192.168.31.201:9000/txt/friend.txt"));
// 设置输出路径
// 要求输出路径必须不存在
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.31.201:9000/wordCount/1"));
// 启动
job.waitForCompletion(true);
}
}
package cn.ceshi.test;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
//单词统计,map类
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
String v = value.toString();
String[] s = v.split(" ");
for (String word : s) {
context.write(new Text(word), new IntWritable(1));
}
}
}
package cn.ceshi.test;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
//单词统计reduce
public class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text arg0, Iterable<IntWritable> arg1,
Reducer<Text, IntWritable, Text, IntWritable>.Context arg2) throws IOException, InterruptedException {
// TODO Auto-generated method stub
int sum = 0;
for (IntWritable val : arg1) {
sum +=val.get();
}
arg2.write(arg0, new IntWritable(sum));
}
}
#打成jar包提交到集群上
[root@hadoop01 test]# hadoop jar wordCounts.jar cn.ceshi.test.WordCountDriver
20/04/23 21:48:22 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
20/04/23 21:48:22 INFO input.FileInputFormat: Total input paths to process : 1
20/04/23 21:48:22 INFO mapreduce.JobSubmitter: number of splits:1
20/04/23 21:48:22 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1587435499369_0001
20/04/23 21:48:23 INFO impl.YarnClientImpl: Submitted application application_1587435499369_0001
20/04/23 21:48:23 INFO mapreduce.Job: The url to track the job: http://hadoop01:8088/proxy/application_1587435499369_0001/
20/04/23 21:48:23 INFO mapreduce.Job: Running job: job_1587435499369_0001
20/04/23 21:48:34 INFO mapreduce.Job: Job job_1587435499369_0001 running in uber mode : false
20/04/23 21:48:34 INFO mapreduce.Job: map 0% reduce 0%
20/04/23 21:48:59 INFO mapreduce.Job: map 100% reduce 0%
20/04/23 21:49:09 INFO mapreduce.Job: map 100% reduce 100%
20/04/23 21:49:09 INFO mapreduce.Job: Job job_1587435499369_0001 completed successfully
20/04/23 21:49:09 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=264
FILE: Number of bytes written=235863
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=230
HDFS: Number of bytes written=34
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=23118
Total time spent by all reduces in occupied slots (ms)=7289
Total time spent by all map tasks (ms)=23118
Total time spent by all reduce tasks (ms)=7289
Total vcore-seconds taken by all map tasks=23118
Total vcore-seconds taken by all reduce tasks=7289
Total megabyte-seconds taken by all map tasks=23672832
Total megabyte-seconds taken by all reduce tasks=7463936
Map-Reduce Framework
Map input records=12
Map output records=24
Map output bytes=210
Map output materialized bytes=264
Input split bytes=106
Combine input records=0
Combine output records=0
Reduce input groups=5
Reduce shuffle bytes=264
Reduce input records=24
Reduce output records=5
Spilled Records=48
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=137
CPU time spent (ms)=1310
Physical memory (bytes) snapshot=309305344
Virtual memory (bytes) snapshot=4198117376
Total committed heap usage (bytes)=165810176
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=124
File Output Format Counters
Bytes Written=34
[root@hadoop01 test]#
#查看一下hdfs上结果文件
[root@hadoop01 ~]# hadoop dfs -ls /wordCount/1
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
Found 2 items
-rw-r--r-- 3 root supergroup 0 2020-04-23 21:49 /wordCount/1/_SUCCESS
-rw-r--r-- 3 root supergroup 34 2020-04-23 21:49 /wordCount/1/part-r-00000
[root@hadoop01 ~]# hadoop dfs -cat /wordCount/1/part-r-00000
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
jim 4
lucy 3
rose 5
smith 5
tom 7
[root@hadoop01 ~]#
#对比一下源文件
[root@hadoop01 ~]# hadoop dfs -cat /txt/friend.txt
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
tom rose
tom jim
tom smith
tom lucy
rose tom
rose lucy
rose smith
jim tom
jim lucy
smith jim
smith tom
smith rose[root@hadoop01 ~]#
安装hbase
hadoop01作为主节点Master,hadoop02,hadoop03作为HregionServer
1.主节点解压Hbase安装包
#解压安装包
[root@hadoop01 sorftware]# tar -zxvf hbase-0.98.17-hadoop2-bin.tar.gz
#设置环境变量,便于后面之间使用hbase命令
[root@hadoop01 sorftware]# cat /etc/profile|grep HBASE
HBASE_HOME=/opt/sorftware/hbase
export PATH=$PATH:$ZOOKEEPER_HOME/bin:$FLUME_HOME/bin:$HIVE_HOME/bin:$SQOOP_HOME/bin:$HBASE_HOME/bin:$KAFKA_HOME/bin:$SPARK_HOME/bin
[root@hadoop01 sorftware]# source /etc/profile
2.主节点修改Hbase配置文件
[root@hadoop01 conf]# cd $HBASE_HOME/conf
#1.修改hbase-env.sh
#设置jdk环境
export JAVA_HOME=/usr/local/jdk1.8.0_212
#修改Zookeeper和Hbase的协调模式,hbase默认使用自带的zookeeper,如果需要使用外部zookeeper,需要先关闭。
export HBASE_MANAGES_ZK=false
#2.修改hbase-site.xml,配置开启完全分布式模式
[root@hadoop01 conf]# cat hbase-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://ns/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!--#配置Zookeeper的连接地址与端口号-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
</configuration>
3.配置region服务器,修改conf/regionservers文件,每个主机名独占一行,hbase启动或关闭时会按照该配置顺序启动或关闭主机中的hbase
[root@hadoop01 conf]# cat regionservers hadoop01 hadoop02 hadoop03 [root@hadoop01 conf]#
4.将hadoop01节点配置好的hbase目录scp到hadoop02,03节点上
#拷贝到hadoop02节点
[root@hadoop01 sorftware]# scp hbase-0.98.17-hadoop2 root@hadoop02:$PWD
#拷贝到hadoop03节点
[root@hadoop01 sorftware]# scp hbase-0.98.17-hadoop2 root@hadoop03:$PWD
5.启动hbase
#1.zookeeper与HDFS服务需要先启动,(我这里上面以及启动过了就不在赘述)
#2.在hdfs上创建hbase-site.xml配置文件中hbase.rootdir对应得目录 /hbase
[root@hadoop01 sorftware]# hadoop dfs -mkdir /hbase
#3.在hadoop01节点上启动HregionServer,Hmaster,hadoop02.hadoop03启动HregionServer
[root@hadoop01 sorftware]# hbase-daemon.sh start master
[root@hadoop01 sorftware]# hbase-daemon.sh start regionserver
[root@hadoop02 zookeeper-3.4.8]# hbase-daemon.sh start regionserver
[root@hadoop03 ~]# hbase-daemon.sh start regionserver
#jps查看进程
hadoop01
[root@hadoop01 test]# jps
8421 DFSZKFailoverController
8533 ResourceManager
8645 NodeManager
27269 HMaster#Hbase主节点进程
27718 HRegionServer#从节点进程
8039 DataNode
7305 QuorumPeerMain
8233 JournalNode
40459 Jps
7933 NameNode
#hadoop02,hadoop03
[root@hadoop02 ~]# jps
8177 JournalNode
8098 DataNode
8026 NameNode
8315 DFSZKFailoverController
23468 Jps
8397 NodeManager
7679 QuorumPeerMain
[root@hadoop03 ~]# jps
8016 DataNode
8209 NodeManager
11911 ResourceManager
12455 HRegionServer
12631 Jps
7722 QuorumPeerMain
8109 JournalNode
6.通过浏览器访问http://hadoop01:60010来访问web界面,通过web见面管理hbase
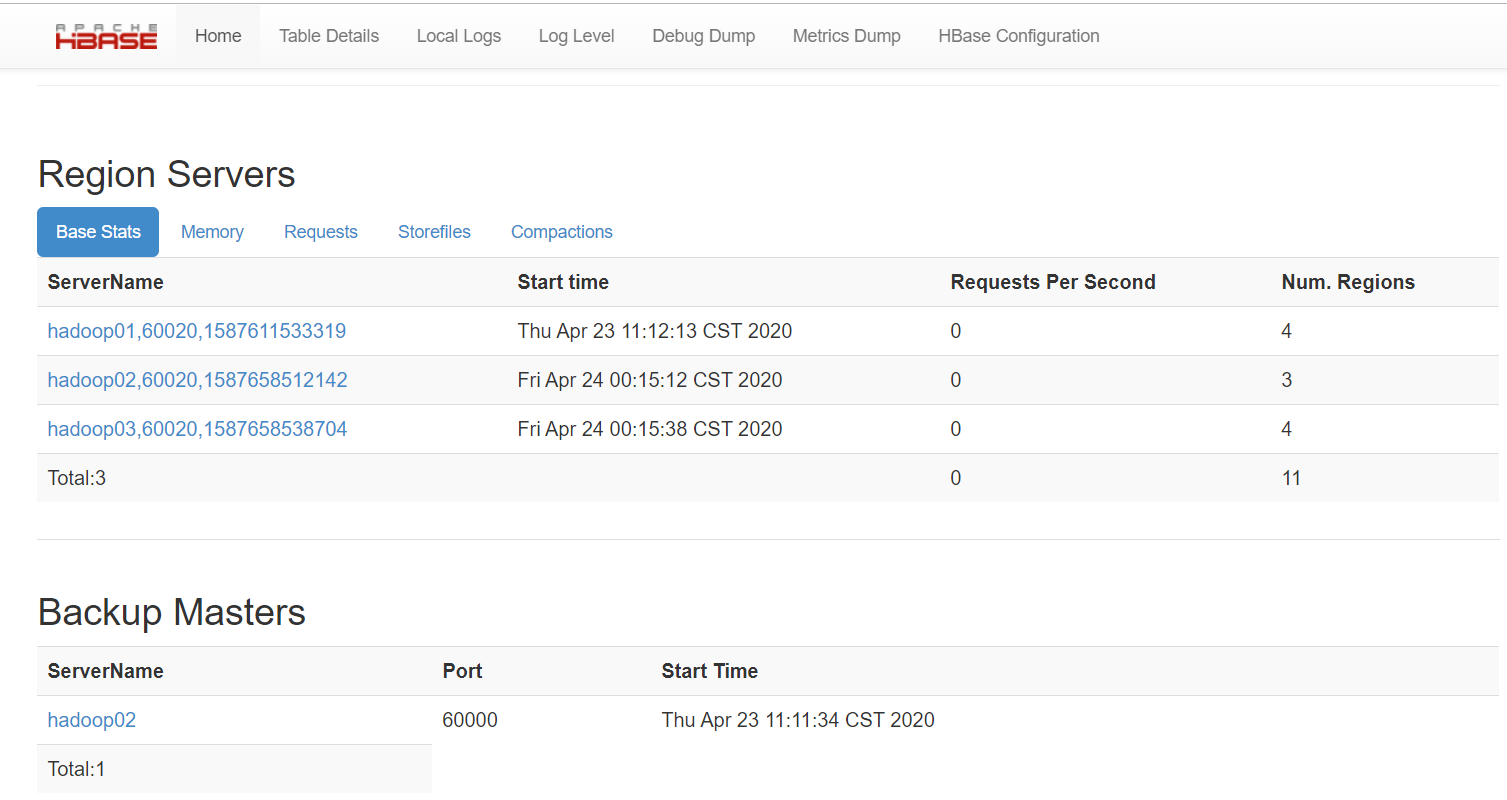
image.png
安装hive
1.安装JDK(已完成)
2.安装Hadoop(已完成)
3.配置JDK和Hadoop的环境变量(以配置)
4.下载Hive安装包
5.解压安装hive,配置环境变量
[root@hadoop01 sorftware]# tar -zxvf apache-hive-1.2.0-bin.tar.gz
#这里我做了一个软链接方便hive目录的操作,也可以直接把hive名称进行更改
[root@hadoop01 sorftware]#ln -s apache-hive-1.2.0-bin hive
[root@hadoop01 sorftware]# cat /etc/profile|grep HIVE_HOME
HIVE_HOME=/opt/sorftware/hive
export PATH=$PATH:$ZOOKEEPER_HOME/bin:$FLUME_HOME/bin:$HIVE_HOME/bin:$SQOOP_HOME/bin:$HBASE_HOME/bin:$KAFKA_HOME/bin:$SPARK_HOME/bin
[root@hadoop01 sorftware]#
6.配置hive-site.xml,cd $HIVE_HOME/conf
[root@hadoop01 conf]# cat hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<!-- Hive 元数据库的jdbc连接bc -->
<value>jdbc:mysql://192.168.31.200:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<!-- mysql驱动名称 -->
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<!-- 元数据数据库用户名-->
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<!-- 元数据数据库用户密码-->
<value>root</value>
</property>
<property>
<name>hive.support.concurrency</name>
<value>true</value>
</property>
<property>
<name>hive.exec.dynamic.partition.mode</name>
<value>nonstrict</value>
</property>
<property>
<name>hive.txn.manager</name>
<value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value>
</property>
<property>
<name>hive.compactor.initiator.on</name>
<value>true</value>
</property>
<property>
<name>hive.compactor.worker.threads</name>
<value>2</value>
</property>
</configuration>
7.安装mysql管理hive元数据,便于多用户使用(hive默认使用derby存储管理元数据,但是不能多用户并发使用 ),将mysql驱动包上传到hive安装目录的lib目录下
安装mysql过程略
8.启动Hive
进入hive 的bin目录,执行:sh hive
如果出现:
Access denied for user ‘root’@‘192.168.31.200’ (using password: YES)这个错误,指的是当前用户操作mysql数据库的权限不够。
进入到mysql数据库,进行权限分配,执行:
grant all privileges on *.* to 'root'@'hadoop01' identified by 'root' with grant option;
grant all on *.* to 'root'@'%' identified by 'root';
然后执行:
flush privileges;
注意:如果不事先在mysql里创建hive数据库,在进入hive时,mysql会自动创建hive数据库。但是注意,因为我们之前配置过mysql的字符集为utf-8,所以这个自动创建的hive数据库的字符集是utf-8的。
但是hive要求存储元数据的字符集必须是iso8859-1。如果不是的话,hive会在创建表的时候报错(先是卡一会,然后报错)。
解决办法:在mysql数据里,手动创建hive数据库,并指定字符集为iso8859-1;
进入mysql数据库,然后执行:create database hive character set latin1;
以上步骤都做完后,再次进入mysql的hive数据,发现有如下的表:
mysql> use hive;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+---------------------------+
| Tables_in_hive |
+---------------------------+
| BUCKETING_COLS |
| CDS |
| COLUMNS_V2 |
| COMPACTION_QUEUE |
| COMPLETED_TXN_COMPONENTS |
| DATABASE_PARAMS |
| DBS |
| DB_PRIVS |
| DELEGATION_TOKENS |
| FUNCS |
| FUNC_RU |
| GLOBAL_PRIVS |
| HIVE_LOCKS |
| IDXS |
| INDEX_PARAMS |
| MASTER_KEYS |
| NEXT_COMPACTION_QUEUE_ID |
| NEXT_LOCK_ID |
| NEXT_TXN_ID |
| NOTIFICATION_LOG |
| NOTIFICATION_SEQUENCE |
| NUCLEUS_TABLES |
| PARTITIONS |
| PARTITION_EVENTS |
| PARTITION_KEYS |
| PARTITION_KEY_VALS |
| PARTITION_PARAMS |
| PART_COL_PRIVS |
| PART_COL_STATS |
| PART_PRIVS |
| ROLES |
| ROLE_MAP |
| SDS |
| SD_PARAMS |
| SEQUENCE_TABLE |
| SERDES |
| SERDE_PARAMS |
| SKEWED_COL_NAMES |
| SKEWED_COL_VALUE_LOC_MAP |
| SKEWED_STRING_LIST |
| SKEWED_STRING_LIST_VALUES |
| SKEWED_VALUES |
| SORT_COLS |
| TABLE_PARAMS |
| TAB_COL_STATS |
| TBLS |
| TBL_COL_PRIVS |
| TBL_PRIVS |
| TXNS |
| TXN_COMPONENTS |
| TYPES |
| TYPE_FIELDS |
| VERSION |
+---------------------------+
53 rows in set (0.00 sec)
mysql>
9.beeline使用
1. beeline是hive提供的一种用于远程连接Hive的方式,其提供了表格形式来进行进行展现 2. 如果使用这种方式,需要先后台启动hiveserver2 sh hive --service hiveserver2 & 3. 连接方式: sh beeline -u jdbc:hive2://hadoop01:10000 -n root
安装spark
spark有很多种运行模式,本次采用Spark自带Cluster Manager的Standalone Client模式(集群)
实现步骤:
1.上传解压spark安装包
2.进入spark安装目录的conf目录,配置spark-env.sh文件
#本机ip地址
SPARK_LOCAL_IP=hadoop01
#spark的shuffle中间过程会产生一些临时文件,此项指定的是其存放目录,不配置默认是在 /tmp目录下
SPARK_LOCAL_DIRS=/home/software/spark/tmp
export JAVA_HOME=/home/software/jdk1.8
3.在conf目录下,编辑slaves文件
hadoop01 hadoop02 hadoop03
4.将spark目录远程scp到其他节点,并更改SPARK_LOCAL_IP
5.启动spark集群
#如果想让hadoop01成为主节点
在hadoop01节点spark sbin目录上执行start-master.sh
##其他节点启动worker进程,执行start-slave.sh
所有节点进程
#hadoop01节点上安装了ZOOKEEPER, HADOOP(HDFS,YARN), HIVE,HBASE, SPARK
[root@hadoop01 sbin]# jps
61409 Jps
8421 DFSZKFailoverController #HDFS主备节点故障切换进程
8645 NodeManager #yarn任务工作节点管理器
27269 HMaster #Hbase主节点进程
27718 HRegionServer #Hbase region进程
8039 DataNode #HDFS数据节点
55239 RunJar #HIVE 的hiveserver2进程,用于远程连接
7305 QuorumPeerMain #Zookeeper进程
8233 JournalNode #HDFS元数据管理进程
61171 Master #Spark主节点
8533 ResourceManager #Yarn 主节点资源管理调度器
61308 Worker #Spark 工作节点
7933 NameNode #HDFS 主节点进程
[root@hadoop01 sbin]#
#hadoop02节点上安装了ZOOKEEPER, HADOOP(HDFS,YARN),HBASE, SPARK组件
[root@hadoop02 ~]# jps
8177 JournalNode
8098 DataNode
19811 HMaster
31990 Worker
23527 HRegionServer
32056 Jps
8026 NameNode
8315 DFSZKFailoverController
8397 NodeManager
7679 QuorumPeerMain
[root@hadoop02 ~]#
#hadoop03节点上安装了ZOOKEEPER, HADOOP(HDFS,YARN),HBASE, SPARK组件
[root@hadoop03 /]# jps
8016 DataNode
8209 NodeManager
11911 ResourceManager
12455 HRegionServer
16729 Worker
7722 QuorumPeerMain
8109 JournalNode
16782 Jps
[root@hadoop03 /]#
说明
记录一下避免遗忘,后面继续把内容完善起来
原文链接:https://www.jianshu.com/p/defe3bfb4946























